
はじめに
AWS認定デベロッパーアソシエイト取得に向けた学習ログです。
学習期間
2020年8月10日~8月16日
学習ログ
API Gateway+Lambda関数を既存バージョンと並行してテストする方法
- エイリアスを利用して、API Gatewayのカナリアリリースを実施する
- カナリアリリースとは
- 新旧環境を並行稼動させ、一部のユーザだけ新バージョンにアクセスさせる手法のこと
- 新バージョンにアクセスするユーザーを、カナリアに見立てている
- 以下も同義
- canary release
- canary deployment
- canary test
- Lambda側でバージョンとエイリアス設定ができる
API Gatewayにステージを追加し、Lambda関数の環境設定を関連付けるためのLambda側の設定
- ステージ変数
- Lambdaエイリアス
AWS KMSの最大データサイズ
- 4KB
- 少量のデータを暗号化できる
- パスワード
- RSAキー
- アプリケーションのデータを暗号化するために設計はされていない
- 少量のデータを暗号化できる
CodeDeployがロールバックした際のデプロイID
- 新しいデプロイID が発行される
- 以前にデプロイされたアプリを、新しいデプロイとして再デプロイすることでロールバックする
- 以前のデプロイバージョンを復元するわけではない
AWS CLIを使ったIAM設定の確認
--dry-run
Kinesis Data StreamsのProvisioned Throughput Exceeded Exceptionエラーへの対処法
- 状況
- Kinesis側のストリーム処理には問題ないパフォーマンスが担保されている
- ストリーム処理されたデータを連携する処理で問題が発生している
- Provisioned Throughput Exceeded Exceptionとは
- プロビジョニングされたスループットが超過した、というエラー
- 大量のデータを処理できていない
- Kinesis自体のパフォーマンス不足というより、データ呼び出し方法が最適でない場合に発生
- 原因A
- シャードにプロビジョニングされたスループットが不十分
- PutRecord要求が処理できていない
- 原因B
- その後のGetRecord処理に対応するパフォーマンスがない
- データレコードを取得するバッチサイズを変更する
- バッチ処理を並行処理する
- その後のGetRecord処理に対応するパフォーマンスがない
- 方針
- コストを最小限に抑えつつ、対策したい
- 解決方法
- エクスポネンシャルバックオフの実施
- Exponential Backoff(指数バックオフ)
- リトライのアルゴリズムのこと
- AWSに限った話ではない
- リクエスト処理が失敗した後のリトライ処理を、許容可能な範囲で徐々に減らして実行する
- 全体のリトライ回数を抑えて、効果的なリトライを実現する
- 1秒後、2秒後、4秒後、、、と指数関数的に待ち時間を加えていく
- Lambdaによるバッチ並行処理の利用
- バッチとは、KinesisのGetRecord処理する単位のこと
- エクスポネンシャルバックオフの実施
Lambda関数からX-Ray SDKを使用してデータが送信されない原因
- Lambda X-Rayトレースが有効化されていない
CodePipeline,CodeCommit,CodeBuild + Beanstalkでデプロイ時間を短縮する方法
- 要件
- 50個のEC2インスタンス
- 大規模なAurora
- やりたいこと
- 依存関係を解決するためにデプロイ時間が長い
- これを短縮したい
- 実現方法
- CodeBuildの最後の段階でソースコードの依存関係をバンドルする
X-Rayトレースにインデックスを付けてトレース情報を取得しやすくする方法
- Annotation(注釈) をつける
- subsegmentを任意のキーで絞り込みできるようになる
- フィルタ式を使って、検索できるようになる
annotation.response_status_code = 200など
Lambda関数側でコードの依存関係を設定してアップロードの準備をする方法
- Lambda関数と依存関係を1つのフォルダでZIP化する
CloudFormationでのLambda関数の指定方法
- Lambda関数をZIP化してS3にアップロードする
AWS::Lambda::Functionで参照する
HogeFunc:
Type: "AWS::Lambda::Function"
Properties:
Code:
S3Bucket:
Fn::ImportValue:
!Sub "fuga-${ENV}-lambda"
S3Key: HogeFunc.zip
FunctionName: !Sub "${ENV}_HogeFunc"
Handler: lambda_function.lambda_handler
MemorySize: 128
- 依存関係がない場合は、直接コードを記述する
AWS::Lambda::FunctionにLambda関数コードを書く- python,node.jsの場合に限る
AWS SAMでS3バケットの読み取りアクセス権を付与する方法
S3ReadPolicyを付与する- AWS SAMでは、事前にポリシーのテンプレートがリスト化されて用意されている
DynamoDBでのスロットルエラーの原因
- 実施したこと
- RCU、WCUをプロビジョニング
- 計算上では十分な設定
- LSI、GSIを追加
- 後ほど、LSI、GSIを追加したテーブルでスロットルエラーが発生
- RCU、WCUをプロビジョニング
- 考えられる原因
- GSIにより、多くのRCUとWCUをプロビジョニングする必要がある
- ベースのテーブルと、GSIの両方に書き込むため、WCUがベーステーブル以上に必要になる
- GSIは、検索時にもRCUを多く消費する
- DynamoDBのキーの種類
- 暗黙的なキー(ハッシュキー、またはハッシュキー+レンジキー=複合キー)
- パーティションを分けるキー
- 同じハッシュキーを持つアイテムは、同じパーティションに保存される
- 1テーブルに付き1個
- 明示的に定義した、ローカルセカンダリインデックス
- 1テーブルに付き5個
- 明示的に定義した、グローバルセカンダリインデックス
- 1テーブルに付き5個
- 暗黙的なキー(ハッシュキー、またはハッシュキー+レンジキー=複合キー)
- LSIとは
- 複合キーテーブルにしか使用できない
- ハッシュキーのみのテーブルには利用できない
- テーブル作成時にのみ定義できる
- 同一のハッシュキーで、異なるレンジキーを設定すること
- 複合キー
Id+ReplyDateTime
- LSI
Id+PostedBy
- 同一のハッシュキー、つまり、同じパーティション内での話になるので、「ローカル」
- そして、異なるレンジキーを設定するので、「セカンダリ」インデックスとなる。
- 複合キー
- 複合キーテーブルにしか使用できない
- GSIとは
- テーブルに対して自由に追加できるインデックス
- ハッシュキーテーブルにも使用できる
- 複合キーテーブルにも使用できる
- テーブル作成後でも任意のタイミングで追加できる
- テーブル自体のスループットとは別に、GSI用のスループットも指定する
- つまり、LSIよりもスループットの消費量が大きい
- GSIとは、裏では別途新しいDynamoDBテーブルを作成し、整合性が取れるように更新を行っている仕組み(かもしれない)
- テーブルに対して自由に追加できるインデックス
$ aws dynamodb update-table \
--table-name ProductCatalog \
--attribute-definitions \
AttributeName=ProductCategory,AttributeType=S \
AttributeName=Title,AttributeType=S \
AttributeName=BicycleType,AttributeType=S \
AttributeName=Price,AttributeType=N \
--global-secondary-index-updates '[{
"Create": {
"IndexName": "ProductCategory-Title-index",
"KeySchema": [
{ "AttributeName": "ProductCategory", "KeyType": "HASH" },
{ "AttributeName": "Title", "KeyType": "RANGE" }
],
"Projection": { "ProjectionType": "ALL" },
"ProvisionedThroughput": { "ReadCapacityUnits": 1, "WriteCapacityUnits": 1 }
}
}]'
SQSのFIFOキューの順序を保証する設定
- メッセージグループIDの値を、Client_idに設定する
S3から出力されるリスト結果をページ分割するCLIコマンド
- デフォルトのページサイズは1000
- 分割するコマンド
--max-itemsオプション- 指定した項目数のみを表示
--page-sizeオプション- 1回の呼び出しで取得する項目数をへらす
CodeDeploy利用時に、デプロイされるLambda関数が変わる前にSNSで通知を実施したい
BeforeAllowTrafficにて実施する- Lambdaのデプロイの場合、2ステップしか無い
BeforeAllowTrafficAfterAllowTraffic
OAuth,SAMLに類似した認証方法でAPIリクエスト認証をしたい
- API Gatewayの機能のうち、
- トークンベースのLambdaオーソライザー を使用する
- TOKENオーソライザーとも言う
- JSON Webトークン、OAuthトークンなどのベアラートークンで発信者IDを受け取る

また、REQUESTオーソライザーもある。
- リクエストパラメータベースのLambdaオーソライザー
- ヘッダー、クエリ文字列パラメータ、
stageVariables、$context変数の組み合わせで発信者IDを受け取る
- ヘッダー、クエリ文字列パラメータ、
DynamoDBのRCUを抑える設定方法
- 結果整合性読み取りで、クエリ処理を実施する
- Provisioned Throughput Exceeded Exceptionへの対応
- エラーの再試行
- 指数関数バックオフ(エクスポネンシャルバックオフ)を実装して、リトライ回数を縮退する
EC2のPublicIPとPrivateIPを取得する方法
- Curlや、Getコマンドを使用して、
169.254.169.254/latest/meta-data/からメタデータを取得する
S3のデータ暗号化に使用するヘッダー
- クライアントが提供する暗号化キー(SSE-C)を使用したサーバサイド暗号化
- 3つのリクエストヘッダーが使用できる
x-amz-server-side-encryption-customer-key-MD5- base64 エンコードされた128ビットMD5ダイジェストを指定できる
x-amz-server-side-encryption-customer-key- S3でデータ暗号化、復号化するために使用する Base64でエンコードされた256ビットの暗号化キーを指定できる
x-amz-server-side-encryption-customer-algorithm- 暗号化アルゴリズムを指定するヘッダー
- ヘッダーの値は、AES256
ECSに対するAWSリソースのアクセス許可設定
- 状況
- Fargate起動モードで3つのアプリが起動している
- 3つのタスクはそれぞれ異なるAWSリソースにアクセスしている
- 設定方法
- 3つのIAMロールを作成する
- 各タスクで使用するAWSリソースへの許可を設定する
- 3つのECSタスクに割り当てる
- 利点
- 認証情報の分離ができる
APIリクエストにクエリ文字列パラメータを含める必要がある場合の、Lambda+API Gatewayの設定方法
- やりたいこと
- GetCustomerリソースを作成
- GETメソッドを公開してLambda関数を呼び出し
- JSON形式でDynamoDBからデータリストを取得
- 設定方法
- リソースのメソッドリクエストを設定する
- 下記の例の場合、
testリソースに対して、POSTメソッドリクエストを設定している

S3にアクセス可能なIAMロールを持つEC2に、リソースアクセス用のAWS CLIが入っている場合の設定変更方法
- やりたいこと
- S3にアクセスさせたくない
- 設定方法
- EC2のIAMロールを変更する
- AWS CLIで設定されたIAMロールを削除する
X-Rayトレースデータをデバッグアプリに表示できるツールのセットアップ方法
GetTraceSummaries APIを使用して、アプリケーションのトレースIDのリストを取得する- トレースサマリのリストを取得する
- トレースサマリには、トレース全体を識別する情報が含まれる
BatchGetTraces APIを使用して、トレースのリストを取得する- IDで指定されたトレースのリストを取得する
PutTraceSegments APIを使ってセグメントドキュメントをX-Rayに直接送信したい
- セグメントドキュメントに、サブセグメントを含める
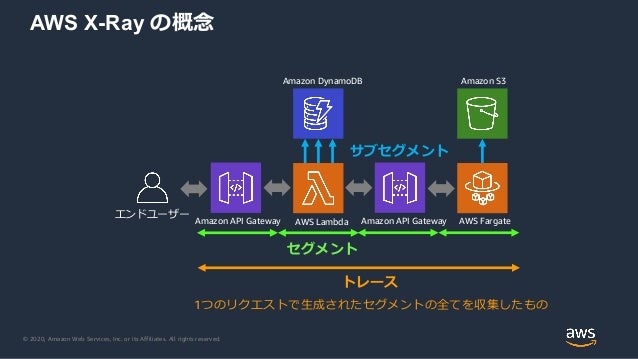
- X-Rayの概念
- トレース
- 単一のリクエストに関するサービスをまたいだ、End-to-endのデータ
- セグメント
- トレースの構成要素
- 個々のサービス
- サブセグメント
- セグメントの構成要素
- 個々のリモートコール
- ローカル処理
- トレース
モバイルゲームアプリの複数プラットフォーム対応、認証サービスが必要。ゲストユーザに一次認証情報を提供したい
- Cognito IDプールを使用する
- 認証されていないIDへのアクセスを許可する

GithubからCodeCommitリポジトリへの移行プロセス
- 新しいCodeCommitリポジトリを作成する
- 既存のGitリポジトリをクローンする
- その内容を新しく作ったCodeCommitリポジトリにpushする
DynamoDBのクエリ処理実装方法
- やりたいこと
- 人事データを管理するCustomerテーブルを作成
- 顧客の口コミデータを管理
- 過去1年にわたり、1ヶ月毎に検索したい
- 実現方法
- customerテーブルの
id+口コミの投稿時間のローカルセカンダリインデックスを生成する
- customerテーブルの
CLIを介して新しいバージョンのElastic Beanstalkをデプロイする方法
- 利用するCLI
- EB CLI
- 手順
- アプリケーションをZIPファイルとしてパッケージ化
eb deployコマンドでデプロイする
- eb deployコマンド
- gitと連携できる
- zipパッケージ化する
- S3と連動はしない
API Gateway で、HTTPSを介してクラアントからの着信要求をバックエンドLambdaに入力値として渡す統合方法
- Lambdaプロキシ統合を使用する
- 理由
- バックエンドがLambdaだから
- バックエンドがEC2や、自作APIの場合は、HTTPプロキシ統合になる
- 設定が楽(合理的)
- Lambdaプロキシ統合は、API Gateway 側に仕事を担当させる
- Lambdaから返される値のフォーマットが決まっている
- 自分でマッピングテンプレートを設定する必要がない
- Lambda関数の引数である、
eventにマッピングされる
- バックエンドがLambdaだから
API GatewayのAPIキャッシュを有効化し、バックエンドからのリクエスト数をモニタリングしたい
- 見るべきメトリクス
CacheMissCount- APIキャッシュが有効になっている特定の期間における、バックエンドから提供されたリクエストの数。
- 関連するメトリクス
CacheHitCount- 指定された期間内にAPIキャッシュから配信されたリクエストの数。
オークションアプリにおけるDynamoDBの設定方法
- 要件
- オーナーが、最低許容価格を許可する
- スタッフが入力する、開始入札価格が最小入札価格
- 顧客の、新しい入札価格 > 現在の入札価格よりも大きい
- 設定方法
- DynamoDBの条件付き更新、条件付き書き込みを使用する
開発者のローカルPCからCodeCommitへのアクセス許可方法
- IAMユーザの作成が必要
- 2種類のアクセス方法がある
- SSH
- 新しいSSHキーを生成して、公開鍵を開発者の各IAMユーザに関連付ける
- HTTPS
- HTTPS接続用のGit認証情報を設定する
- IAMユーザのアクセスキーを使用して接続する
- SSH
API Gatewayで、Swagger定義からリソースとメソッドを取り込む方法
- Swaggerとは
- RESTful APIを構築するためのOSS Framework
- AWSコンソールを使用して、Swaggerまたは、OpenAPI定義をAPI Gatewayにインポートできる
- REST API作成時に、インポートできる

- REST API作成時に、インポートできる
Lambda関数とDynamoDBの認証情報を暗号化して保護して、安全に共有したい
- AWS Systems Managerパラメータストア を使用する
- 認証情報の暗号化の方法は2つある
- 設定とシークレットに1つのストアが欲しい場合
- AWS Systems Managerパラメータストアを使用する
- KMSに保存される
- AWS Systems Managerパラメータストアを使用する
- ライフサイクル管理を備えたシークレット専用のストアが欲しい場合
- Secrets Managerを使用する
- KMSに保存される
- Secrets Managerを使用する
- 設定とシークレットに1つのストアが欲しい場合

DynamoDBで個々の書き込み要求に対して影響を受けたテーブルとセカンダリインデックスの値を返答させたい
- 書き込み要求に対して、
ReturnConsumedCapacityパラメータにINDEXESの値を追加する設定を行うTOTAL- 消費されたWCUの総数を返す
INDEXES- 消費されたWCUの総数、テーブル、影響を受けたセカンダリインデックスの小計を返す
NONE- WCUの詳細は返さない(デフォルト)
- 読み込み要求
TOTALを指定することで、GetItemで消費される読み込みキャパシティユニットの値を返すこともできる
$ aws dynamodb get-item \ --table-name ProductCatalog \ --key --return-consumed-capatity TOTAL
AWSとオンプレを利用したアプリにて、SAML2.0によるエンタープライズIDプロバイダを使用してサインインしたい
- 実現方法
- IDフェデレーションとCognitoの統合を有効にする
- ID federation(同盟、連合)
- IDで1回認証すれば、その認証情報を使って、許可されているすべてのサービスを使えるようにする仕組みのこと
- CognitoのIDプールにて設定できる
- ID federation(同盟、連合)
- AWS Single Sign-On により、Organizations のすべてのアカウントへの SSOアクセスとユーザアクセス権の一元管理を実行する
- IDフェデレーションとCognitoの統合を有効にする
- CognitoのIDプール
- Cognitoリリース時からある古い機能
- Cognitoリリース時からある古い機能
- AWS Single Sign-Onとは
- AWS Organizations、AWS Directory Serviceと連携して、社内Active Directoryのユーザで複数のAWSコンソールにログインできる
- SAML対応のSaaSサービスにシングルサインオンできる

Lambda、API Gateway、DynamoDBのサーバレスアプリにてHTTP504エラーになる原因
- 要件
- Javaフロントエンドアプリにデータを送信して表示する
- アクセスピークに達すると、504エラーが発生する
- 考えられる原因
- Lambda関数が29秒以上実行されているため、API GatewayRequestがタイム・アウトしている
- ピークアクセスまでは動いているため、統合の失敗ではない
- 詳細
INTEGRATION_FAILURE- 504エラー
- 統合が失敗した場合
- 504エラー
INTEGRATION_TIMEOUT- 504エラー
- 統合がタイムアウトした場合
- タイムアウト値は、50ミリ秒~29秒まで
- 504エラー
Organizationsを利用して複数のAWSアカウントを管理・運用し、最小限の労力でCloudFormationテンプレートの更新を行う方法
- CloudFormationのスタックセットを使う
- 複数のAWSアカウント、リージョンに対してCloudFormationのスタックを作成できる機能
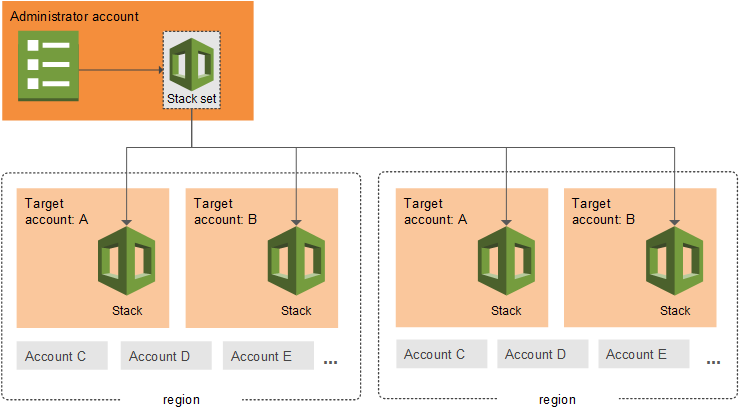

- 複数のAWSアカウント、リージョンに対してCloudFormationのスタックを作成できる機能
依存関係をまとめたLambda関数のデプロイパッケージを小さくする方法
- 状況
- 解凍すると、312MBある
- Lambda関数をデプロイするとエラーになる
- 解決方法
- 解凍後のLambda関数を250MB以下にしてアップロードする
- Lambdaレイヤー含め、250MB以下
- 余分なファイルを
/tmpディレクトリにアップロードする- /tmpディレクトリの制限は、512MGまで
- 解凍後のLambda関数を250MB以下にしてアップロードする
EC2を設定する手間をかけずに、DockerコンテナをAWSにデプロイしたい
- 実現方法
- ECSのFargate起動タイプを使用する
- Fargateとは
- コンテナ向けサーバレスコンピューティング
- ECSと一緒に使う
- EC2でサーバやクラスターを管理せずコンテナが使える
- 仮想マシンのクラスターをプロビジョニング、設定、スケールする必要がない
- 使い方
- ECSにアクセス
- クラスターを作成
- ECRリポジトリにイメージをプッシュ
- Elastic Container Registry
- コンテナのイメージを保存して追う場所
- docker hubみたいなもの
- タスク定義
- Fargateを選択
- メモリとCPUを割り当て
- コンテナ名を作成
- タスクの実行
- Fargateを選択
ECS+CloudFormationでのトラブルシューティング
- 発生した事象
- CloudFormationでリソース管理
- AutoScalingグループを設定したECSクラスターを展開する
- 2つのクラスターを管理
- ECSクラスター1
- パラメータ入力を使ったCloudFormationテンプレートで構築
- ECSクラスター2
- パラメータ入力を使ったCloudFormationテンプレートで構築
- すべてのインスタンスがクラスター1で起動した
- ECSクラスター1
- 考えられる原因
- ブートストラップ中に、クラスター名パラメータが、ファイル
/etc/ecs/ecs.configに反映されていない- ECSクラスターを作成する際に、高度な設定、からクラスター名を記載する
- EC2インスタンスのユーザーデータを記述
- ECSコンテナエージェント設定を行う
- 起動したEC2インスタンスがECSクラスタの一部であることをコンテナエージェントに伝える必要がある
ECS_CLUSTERに設定する値は、ECSクラスタ名と一致させる必要がある
- ECSクラスターを作成する際に、高度な設定、からクラスター名を記載する
- ブートストラップ中に、クラスター名パラメータが、ファイル
#!/bin/bash echo ECS_CLUSTER=demo-cluster >> /etc/ecs/ecs.config
CI/CD環境にて、自動実行しつつ、コードレビュー等は上位者による認証を行いたい
- 実現方法
- フロー全体に対して1つのCodePipelineを作成
- 承認ステップを追加する
EC2の平均RAM使用量によるAutoScalingグループの設定を行いたい
- 実現方法
- EC2インスタンスに対して、Cloud Watchのカスタムメトリクスを作成する
- 内部情報は標準メトリクスでは見れない
- メモリ使用率
- ディスクスペース使用量
- 内部情報は標準メトリクスでは見れない
PutMetricDataを使用してデータの送信設定を行う- そのメトリクスに対してアラームを設定する
- EC2インスタンスに対して、Cloud Watchのカスタムメトリクスを作成する
カスタムメトリクスを設定するために必要な手順 docs.aws.amazon.com
IoTストリーミングデータを処理して、他のソースにリアルタイムのクエリ解析結果を継続的に送信したい
- 実現方法
- Kinesis Data Streams
- Kinesis Data Analytics
- Kinesis Data Analyticsとは
- ストリーミングデータに対するリアルタイム分析ができるマネージドサービス
ズンドコきよし判定もできるwwwwwwwww
APIコールのパフォーマンスを改善したい
- API Gateway のAPIキャッシュを有効にする
- ステージから設定可能

- ステージから設定可能
効果的なBeanstalkの設定
- 要件
- SQSキューによるポーリング処理を実施
- EC2インスタンスがポーリングを受け取る
- 高負荷でも応答性を維持するために長時間かかるコンポーネントを分離したい
- 実現方法
- ワーカー環境を構築する
RDSの拡張モニタリングで取得できるメトリクス
- RDSの標準モニタリング
- CPU使用率
- DB接続数
- 空きストレージ容量
- 利用可能メモリ
- I/Oスループット
- RDSの拡張モニタリングとは
- ログインできないOSの詳細情報を取得できる
- RDS Childプロセス(子プロセス)
- OSプロセス
- などなど
- ログインできないOSの詳細情報を取得できる
Beanstalkがデプロイ時に使用するサービス
- CodePipeline
- Beanstalkを使用してコードをデプロイするように設定ができる
- CloudFormation
Route53を使用してS3バケットにホストされているWEBサイトにトラフィックをルーティングするための前提条件
- ドメインネームとバケット名を同じにする
- 独自ドメインでWEB公開する場合、バケット名=FQDNである必要がある
- 登録済みドメインネームであること